The source code for this project is available on GitHub.
1 Load Nodes and Features
We start by loading the street graph and features prepared in the first three parts of the project:
Code
import pickleimport pandas as pdfrom lib.data import load_timesteps, create_data_tensorfile_path ='../../data/processed/baltimore_street_graph.gpickle'withopen(file_path, 'rb') as f: G = pickle.load(f)num_nodes = G.number_of_nodes()print(f'Loaded street graph with {num_nodes} nodes and {len(G.edges)} edges')file_path ='../../data/processed/timesteps.csv.gz'timesteps = load_timesteps(file_path)print(f'Loaded {len(timesteps)} timesteps')data_tensor = create_data_tensor(timesteps, num_nodes)print(f'Loaded data tensor: {data_tensor.shape}')
Loaded street graph with 1177 nodes and 3469 edges
Loaded 278134 timesteps
2 Prepare Training, Validation, and Test Data
Here we split the crime events into separate datasets for training (70%), validating (15%), and testing (15%). The slices are taken in chronological order, so we can determine if using historic data (the first 70%) to train a model can make accurate predictions of more recent events (contained in the remaining 30%).
Validation data is used to evaluate the model’s performance after every training cycle. The training process can halt early if validation performance starts to decline, saving time and resources. Checking progress with validation data also helps avoid overfitting, where the model simply memorizes the training data without being able generalize to new, previously-unseen data.
Test data is used to evaluate the model’s final quality after all training cycles complete.
Code
import importlib;import lib.data; importlib.reload(lib.data)from lib.data import create_training_datasetstraining_data, validation_data, test_data = create_training_datasets( data_tensor, training_fraction=0.7, validation_fraction=0.15, lookback_timesteps=14)print(f'Created training data with {len(training_data)} timesteps')print(f'Created validation data with {len(validation_data)} timesteps')print(f'Created test data with {len(test_data)} timesteps')# Smaller batch sizes can lead to noisier gradient updates, helping the model escape local minima,# potentially leading to better generalization.batch_size =30training_data = training_data.batch(batch_size)validation_data = validation_data.batch(batch_size)test_data = test_data.batch(batch_size)
Creating total_windows: 3232 with 14 lookback timesteps
Created training data with 2248 timesteps
Created validation data with 470 timesteps
Created test data with 472 timesteps
3 Set Default Hyperparameter Values
Hyperparameters adjust the learning behavior of the model and control the training process itself. Here we lay out starting values, based on those used in the GLDNet paper.
# Controls the size and complexity of the GatedRelu component, which learns spatial featuresdefault_num_gated_relu_layers =2default_num_gated_relu_hidden_units =8# Controls the size and complexity of the LocalizedDiffusionNetwork component, which learns temporal featuresdefault_num_ldn_layers =5default_num_ldn_hidden_units =4# Defines how the model learns from prediction errorsdefault_loss_rho =0.03rho_tuning_step =0.005
4 Build Tunable Model
The next function builds the GLDNet model using the code written in part 3, wrapping all of its tunable parameters with keras_tuner.HyperParameters from the keras tuner library.
keras_tuner will build new versions of our model while conducting an automatic search for the most optimal combination of hyperparameters. We will use Hit Rate Accuracy to evaluate the effectiveness of each combination. See part 3 for details.
from lib.model import build_modelfrom lib.metrics import HitRateMetricimport keras_tunermetrics = [HitRateMetric(num_nodes, coverage=0.2)]def build_tunable_model(hp, **kwargs):"""Sets up the GLDNet model with hyperparameters that can be tuned by the Keras Tuner""" num_gated_relu_layers = hp.Int("num_gated_relu_layers", min_value=1, max_value=4, step=1, default=default_num_gated_relu_layers) num_gated_relu_hidden_units = hp.Choice("num_gated_relu_hidden_units", [2,4,8,16], default=default_num_gated_relu_hidden_units, ordered=False) num_ldn_layers = hp.Int("num_ldn_layers", min_value=1, max_value=7, step=1, default=default_num_ldn_layers) num_ldn_hidden_units = hp.Choice("num_ldn_hidden_units", [2,4,8,16], default=default_num_ldn_hidden_units, ordered=False) loss_rho = hp.Float("loss_rho", min_value=0.005, max_value=0.035, step=rho_tuning_step, default=default_loss_rho) hyperparameters = {'num_gated_relu_layers': num_gated_relu_layers,'num_gated_relu_hidden_units': num_gated_relu_hidden_units,'num_ldn_layers': num_ldn_layers,'num_ldn_hidden_units': num_ldn_hidden_units,'loss_rho': loss_rho } model = build_model(G, metrics, **hyperparameters)return model
5 Setup Local Hyperparameter Search
Instead of making random guesses, we will use the Hyperband algorithm, which speeds up the search through “..adaptive resource allocation and early-stopping.” It tries many different variable combinations, quickly discarding those that are not promising.
val_hit_rate is the Hit Rate Accuracy metric applied to the validation set during training. Low val_hit_rate values can trigger early stopping.
objective = keras_tuner.Objective("val_hit_rate", direction="max")tuner = keras_tuner.Hyperband( hypermodel=build_tunable_model, objective=objective, hyperband_iterations=5, # number of times to run the entire hyperband process factor=2, # reduction factor for the number of configurations & epochs in successive rounds overwrite=False, directory="./tuning/", project_name="crimegraph", max_epochs=25# maximum number of epochs to train each model in any trial)
6 Review Search Space
keras_tuner reports the five hyperparameters along with the ranges of values to be searched by the Hyperband algorithm:
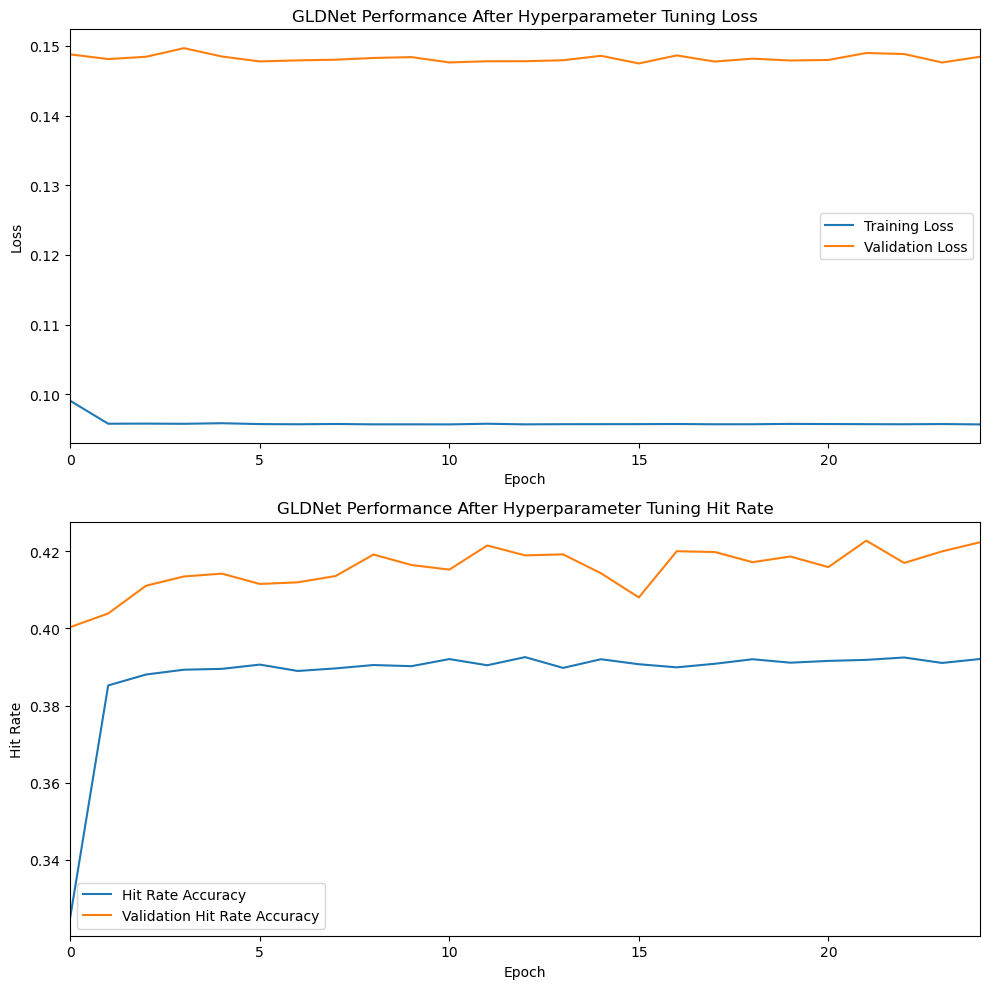
The model can now be trained from scratch using the best set of hyperparameters and presented with test data to demonstrate hit rate prediction acccuracy for events that it has never seen before.
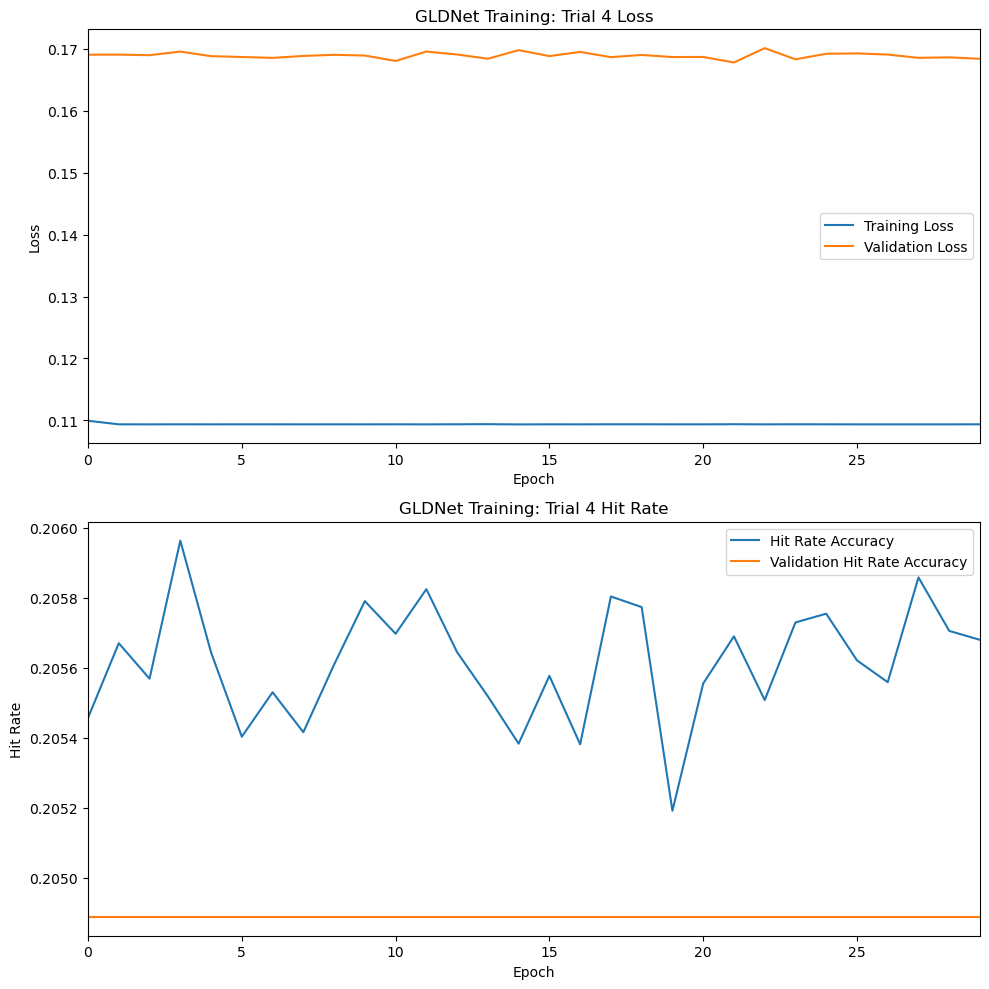
40.5% hit rate accuracy on the test data is well below the 60% value reported by the GLDnet paper, and the flat loss function indicates that not much learning is occuring. To improve accuracy, I began a long series of experiments to adjust the model architecture while searching for new hyperparameter combinations. Most of the experimental results looked like this:
image-2.png
Loss rates were usually flat, while validation accuracy fluctuated, suggesting that the model was not generalizing well. The most significant model change I tried was adding Dropout and Regularization layers, but this seemed to overcomplicate the architecture and resulted in even worse, more unstable performance.
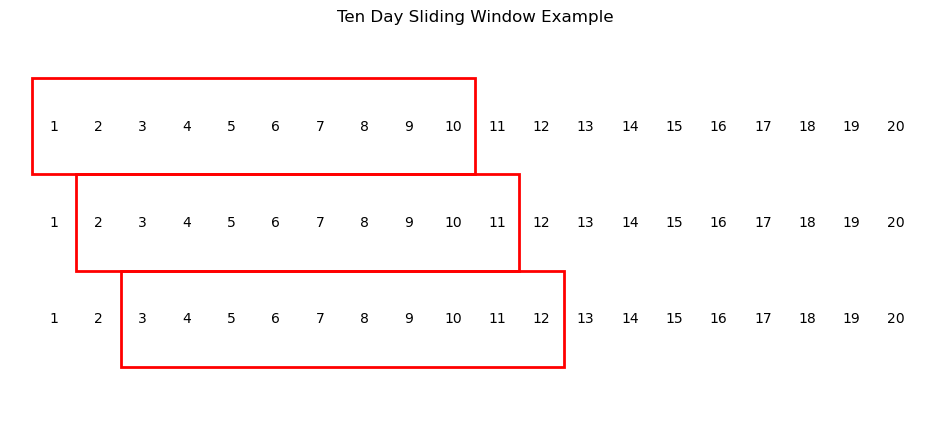
9 Augmenting With a Sliding Window
I re-examined the training process and realized that the model was being trained on a relatively small amount of data. Each batch presented to the model contained a series of continuous timesteps, with no overlap between batches. The model would use training events from days 1-10 to make a prediction for day 11, and use events from days 11-20 to make a prediction for day 211.
I modified the data loading code to return a ‘sliding window’ of events overlapping between batches. The model could now use events from days 1-10 to predict day 11 and use events from days 2-11 to make a prediction for day 12, resulting in many more batches and a much richer dataset.
Code
import matplotlib.pyplot as pltimport matplotlib.patches as patchesdef draw_sliding_window(): fig, ax = plt.subplots(figsize=(12, 5)) ax.axis('off') y_positions = [0, -1, -2] window_starts = [1, 2, 3]for y, window_start inzip(y_positions, window_starts):for x inrange(1, 21): ax.text(x, y, str(x), ha='center', va='center') rect = patches.Rectangle((window_start-0.5, y-0.5), 10, 1, linewidth=2, edgecolor='r', facecolor='none') ax.add_patch(rect) plt.xlim(0, 21) plt.ylim(-3, 1) plt.title('Ten Day Sliding Window Example') plt.show()draw_sliding_window()
10 Training With the Sliding Window
Training accuracy improved immediately with the augmented data, with more stable training losses and validation hit rates.
The best model achieved hit rate accuracy 59% on the test data. The winning hyperparameters were:
Parameter
Value
initial_learning_rate
0.03
loss_rho
0.04
num_ldn_layers
5
num_ldn_hidden_units
4
num_gated_relu_layers
2
num_gated_relu_hidden_units
8
11 Conclusion
After conducting thousands of trials, I believe I have pushed the GLDNet model to learn as much as it can from the SpotCrime data, getting within 1% of the hit rate accuracy reported in the original paper. It may not be possible for this architecture (as I have have implemented it) to learn more. Here are some future project ideas to improve accuracy:
Spatial area selection: the street graph could be expanded to include a larger or smaller selection of streets. Instead of making rectangular cuts of the street grid, clusters of related streets could be selected by Louvain Community Detection or related algorithms.
Augment spatial features: new channels of information known to be predictive of crime events could be added to each street node, such as population density or proximity to the nearest police station.
Augment temporal features: new channels could also be added to each timestep, such as temperature or whether the timestep day is a holiday.
Two feature engineering hyperparameters could also be adjusted via optimization experiments:
Thank you to SpotCrime for allowing me to use their data. Thank you to Yang Zhang and Tao Cheng for publishing their excellent paper which was the inspiration for this project.
Footnotes
The batches are shuffled during each training run, so they are not presented to the model in chronological order↩︎